
In the article Web Performance Optimization: Part 1 - Network and Assets Optimization, I summarized the optimization of network resources from two perspectives: network connectivity and resource loading. Next, I will analyze page rendering and provide an optimization summary after obtaining the page resources.
Rendering process in a nutshell
First, we know that when the network process receives the response headers and detects that the content-type is text/html, it will identify the file as HTML and prepare a rendering process for this request. The subsequent page rendering pipeline will then unfold in this rendering process. We can think of the HTML code as the blueprint for the initial DOM construction of the browser page UI. Whenever a script element is parsed, the browser will stop building the DOM from the HTML and start executing the JavaScript code. When CSS text is received, it will convert the CSS text into stylesheets that the browser can understand. Therefore, the core task of the renderer process is to convert HTML, CSS, and JavaScript into a web page that users can interact with.
HTML Parsing
When the renderer process receives the navigation commit message and starts receiving HTML data, the main thread begins parsing the text string (HTML) and converting it into a Document Object Model (DOM).
The general parsing process is as follows: When the renderer process receives the byte stream from the network process, the HTML parser converts the byte stream into multiple tokens (Tag Tokens and Text Tokens). Tag Tokens are further divided into StartTags and EndTags, for example, <body> is a StartTag, and </body> is an EndTag. By maintaining a token stack structure, the parser continuously pushes and pops new tokens, parsing them into DOM nodes and adding these nodes to the DOM tree.
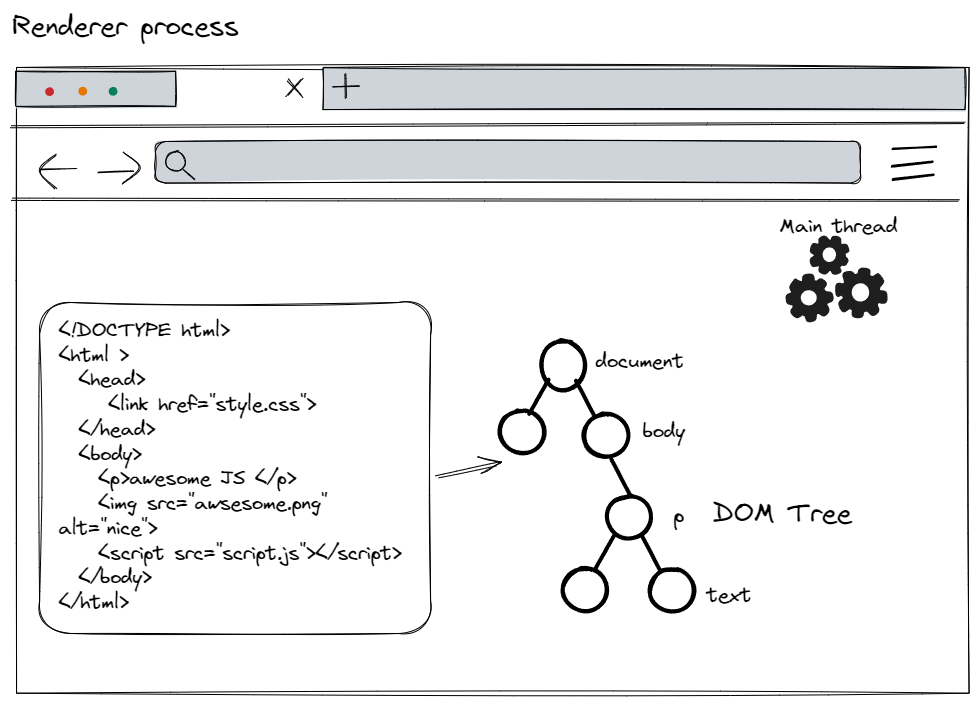
If there is something like <img> or <link> in the HTML document, the preload scanner looks at the Token generated by the HTML parser and sends the request to the network process.
Scripts Parsing
When the HTML parser encounters a <script> tag, it pauses the parsing of the HTML document and must load, parse, and execute the JavaScript code. Why? Because JavaScript can use things like document.write() to change the shape of the document, which alters the entire DOM structure. This is why the HTML parser must wait for the JavaScript to run before it can continue parsing the HTML document.
CSS Parsing
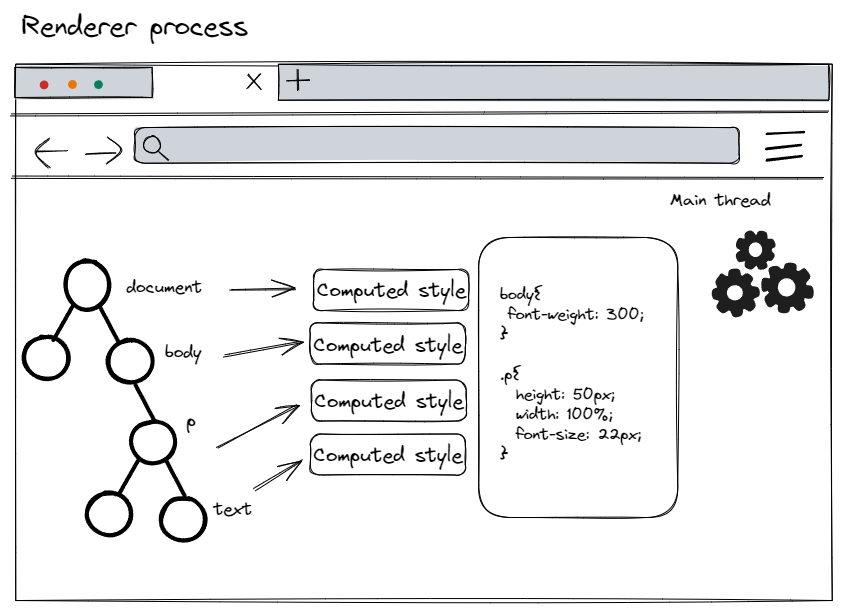
Having the DOM is not enough to know what the page will look like because we can set the styles of page elements in CSS. Just like HTML files, the browser cannot directly understand plain text CSS styles. Therefore, when the rendering process receives the CSS text, it performs a conversion operation, transforming the CSS text into styleSheets that the browser can understand, which we can access using document.styleSheets.
Now that the browser can understand the structure of the CSS style sheets, after standardizing the CSS property values and applying the CSS inheritance and cascading rules, we can calculate the specific styles for each node in the DOM tree.
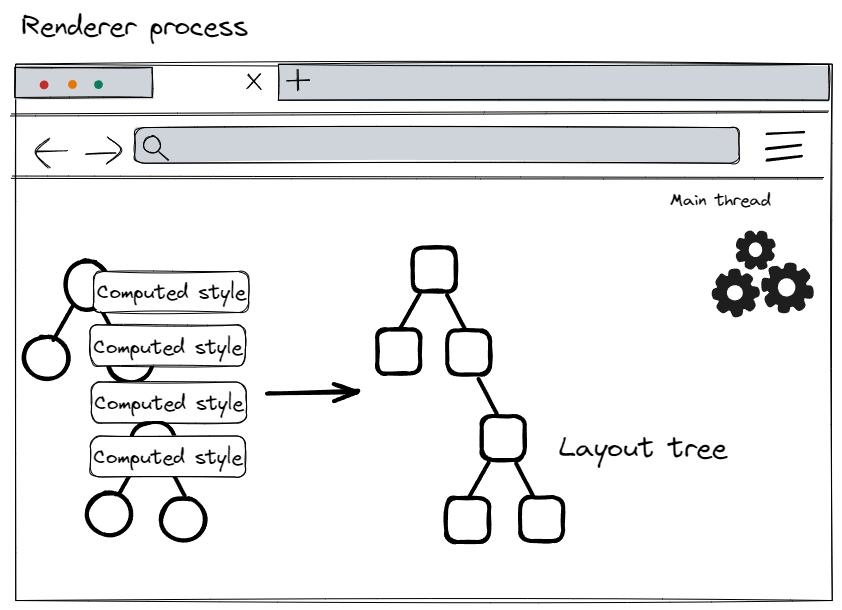
Layout
Now the renderer process knows the structure of the document and the styles of each node, but this is not enough to render the page. It must go through a layout phase. Layout is the process of determining the geometric shapes of elements. The main thread traverses the DOM and calculates styles, creating a layout tree that includes information such as xy coordinates and bounding box sizes. The layout tree may resemble the structure of the DOM tree, but it only contains information related to visible elements on the page. If a node has display: none applied, it will not be part of the layout tree. Similarly, if a pseudo-class like p::before{content:"Hi!"} is applied, it will be included in the layout tree even though it is not in the DOM.
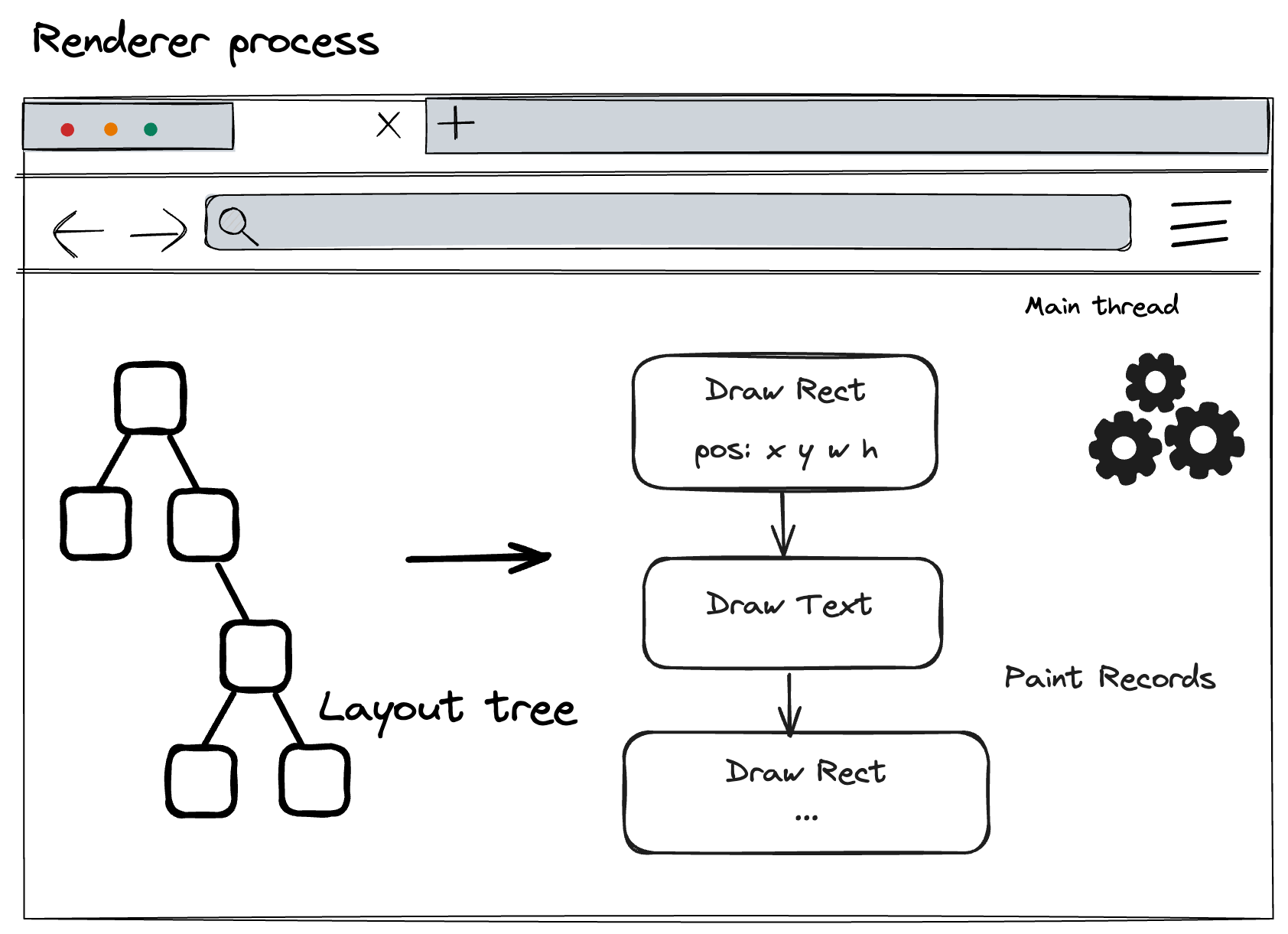
Paint
Having the DOM, style, and layout trees is still not enough to render the page; we also need to know the order in which to draw these nodes. For example, we might set a z-index for certain elements, in which case drawing in the order the elements are written in the HTML would result in incorrect rendering. In this drawing step, the main thread traverses the layout tree to create paint records. Paint records document the drawing process, such as "background first, then text, and finally rectangles."
One of the most important things to remember in the rendering pipeline is to use the results of the previous operation to create new data at each step. For example, if something in the layout tree changes, the drawing order needs to be regenerated for the affected part of the document. This brings us to the concepts of repaint and repaint, which we'll talk about later.
Compositing
Since the browser knows the document's structure, the style of each element, the page's geometry, and the drawing order, how does it draw the page? The simplest way to handle this is by rasterizing parts within the viewport (rasterization can be understood as converting layout information into pixels on the screen). If the user scrolls the page, the raster frame moves, and the missing parts are filled with more rasters (pixels). This is how Chrome handled rasterization when it was first released. However, modern browsers run a more complex process called compositing.
Compositing is a technique that divides different parts of the page into multiple layers, rasterizes them separately, and then combines them into a single page in a separate thread called the compositor thread. If scrolling occurs, since the layers have already been rasterized, all it needs to do is compose a new frame.
Layering
To figure out which elements need to be on which layers, the main thread traverses the layout tree to create a LayerTree. Dedicated layers are generated for CSS transform animations, page scrolling, or for page nodes that use
z-index.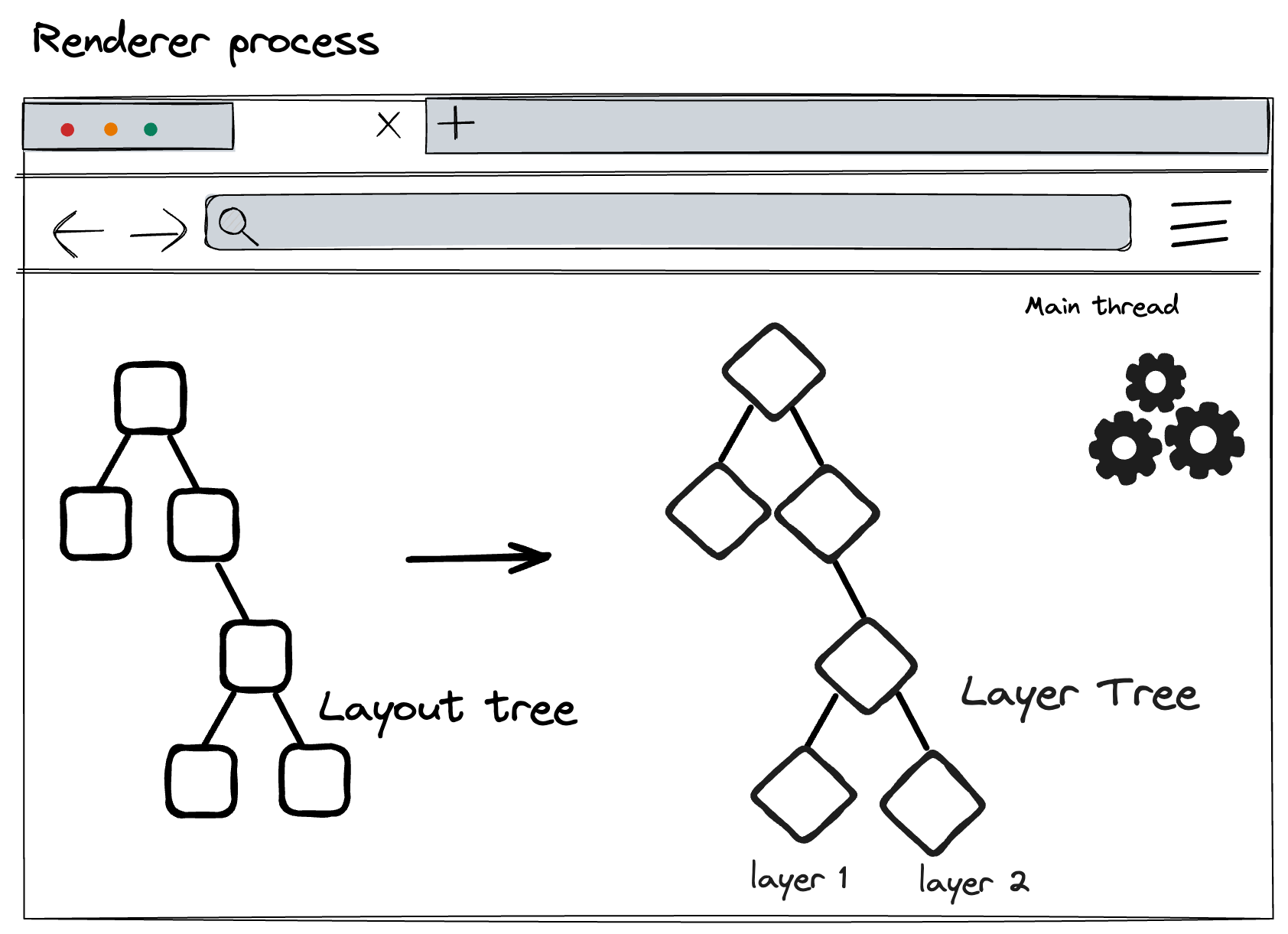
Rasterization
Once the layer tree is created and the drawing order is determined, the main thread submits this information to the compositor thread. The compositor thread then rasterizes each layer. A layer can be as large as the entire length of the page, so the compositor thread divides them into multiple tiles and sends each tile to the raster thread. The raster thread rasterizes each tile and stores them in GPU memory.。
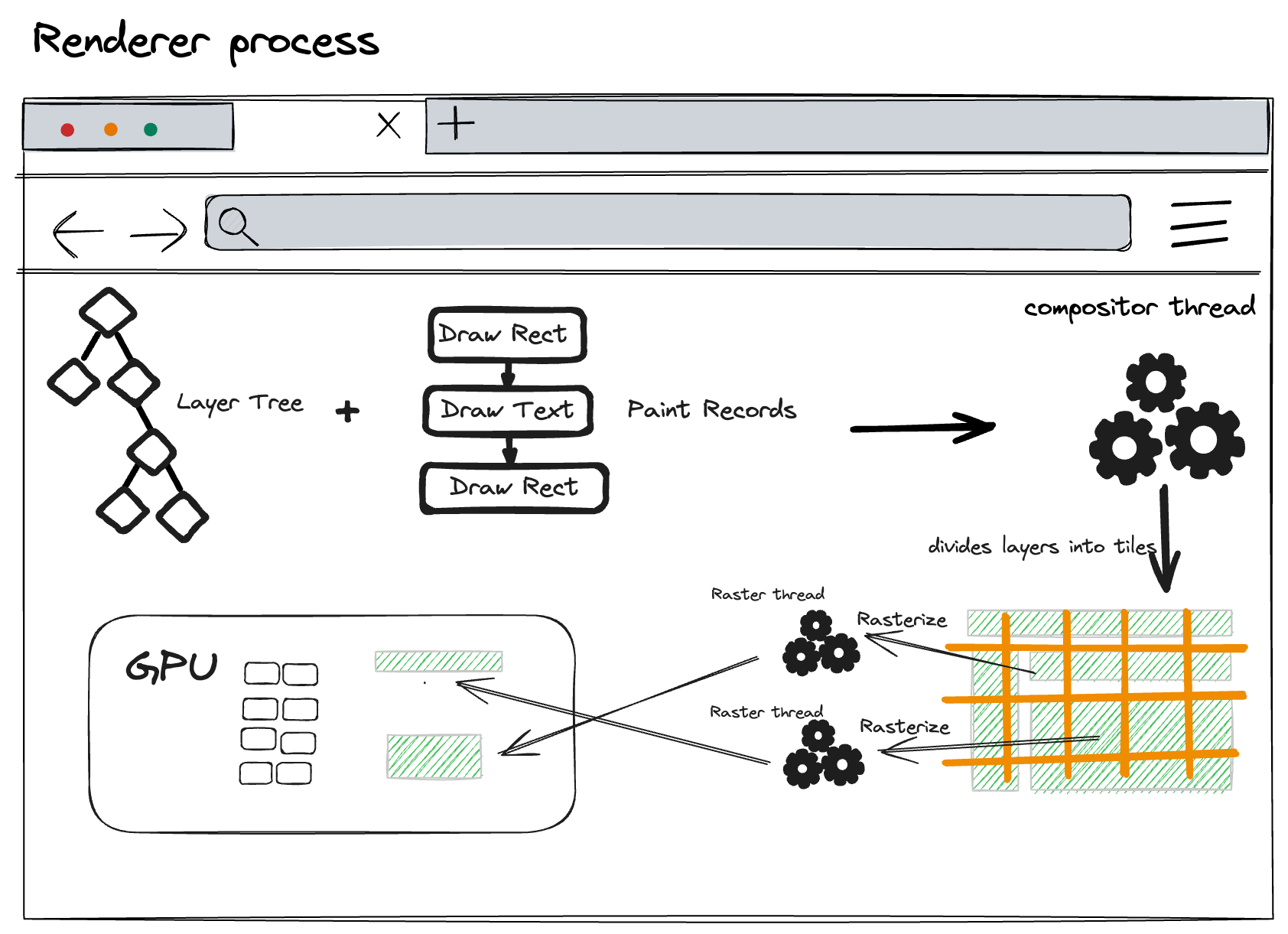
Composition threads can prioritize different raster threads so that things in (or near) the viewport can be rasterized first.
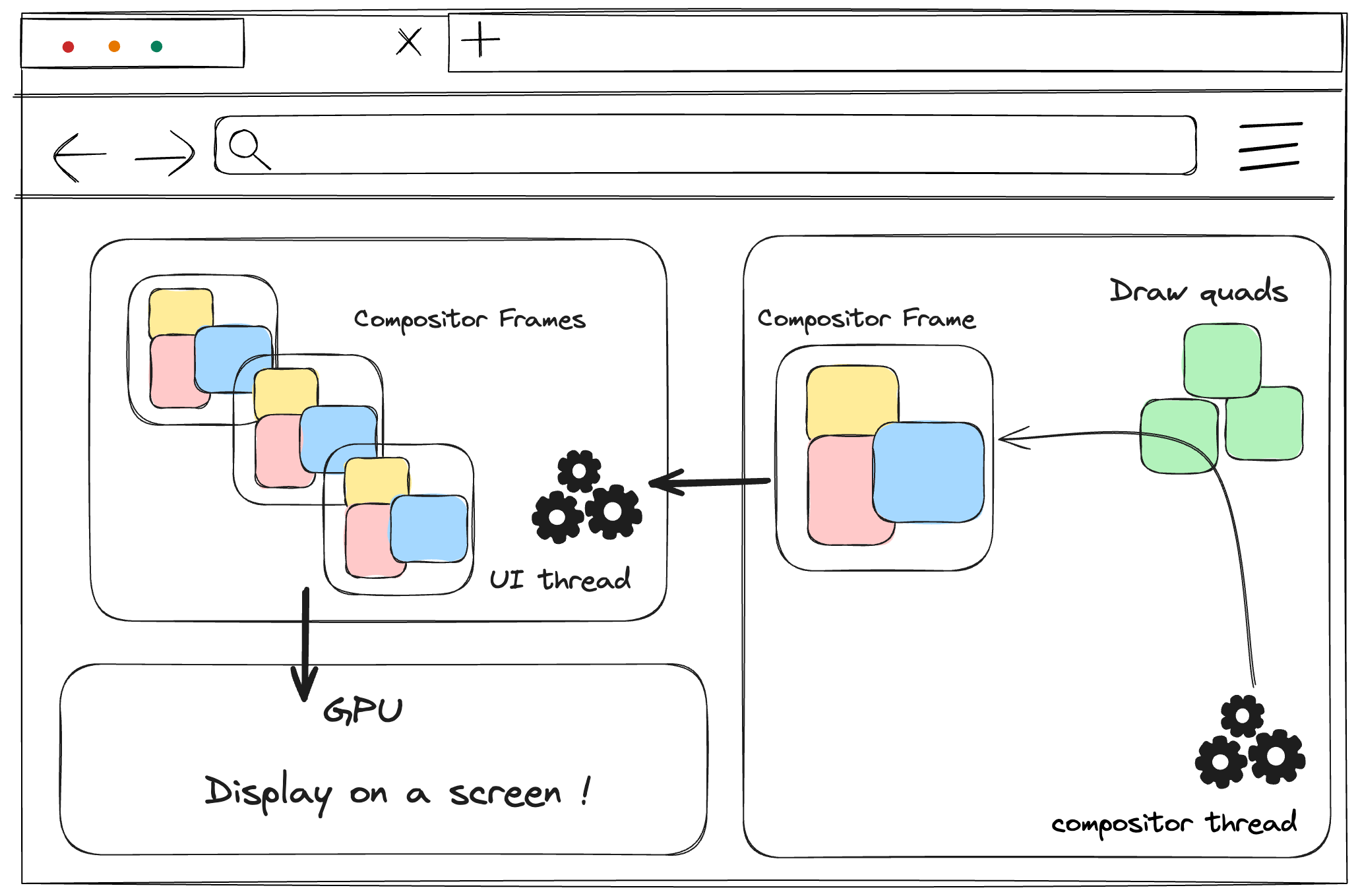
Composite display
Once all tiles are rasterized, the compositor thread will collect information about the tiles (their positions in memory and their positions on the page) to generate a compositing frame (a frame of the page that contains all the tile information).
This compositing frame will be submitted to the browser process via IPC (Inter-Process Communication), and then multiple compositing frames will be sent to the GPU to be displayed on the screen. If there is a screen scroll event, the compositor thread will create the next compositing frame and send it to the GPU.
Since then we have understood the rendering pipeline of a page from the parsing of HTML, JS and CSS to the compositing of the page frames:
HTML Parsing
The renderer process receives the navigation commit message, starts receiving HTML data, and the main thread parses the HTML text string, converting it into a DOM tree.
Scripts Parsing
When the HTML parser encounters a
<script>tag, it pauses the parsing of the HTML document because the browser must load, parse, and execute the JavaScript code before continuing.CSS Parsing
The rendering process receives the CSS text, converts it into styleSheets that the browser can understand, and then calculates the specific styles for each node in the DOM tree after standardizing the CSS property values and applying CSS inheritance and cascading rules.
Layout
The main thread traverses the DOM and calculates styles, creating a layout tree that only contains information related to visible elements on the page.
Paint
The main thread traverses the layout tree to create paint records, documenting the drawing process and determining the order in which to draw the nodes, considering properties like
z-index.Compositing
The page is divided into multiple layers, which are rasterized separately and then combined into a single frame in a separate thread called the compositor thread.
The compositor thread rasterizes each layer, divides them into multiple tiles, and sends each tile to the raster thread.
The raster thread rasterizes each tile and stores them in GPU memory.
The compositor thread collects information about the tiles to generate a compositing frame, which is submitted to the browser process and then sent to the GPU for display.
So how do we achieve performance optimization of page rendering from above steps?
Optimization Methods Derived from the Rendering Pipeline
We can derive the following key points from the rendering pipeline:
Each step in the rendering pipeline uses the result of the previous operation to create new data. For example, if something in the layout tree changes, the paint order for the affected part of the document needs to be regenerated.
Layout is the process of determining the geometric shapes of elements. The main thread traverses the DOM, computes styles, and creates the layout tree.
The composition of page frames is done without involving the main thread. The compositor thread does not need to wait for style calculations or JavaScript execution.
When there are changes on a single layer, the rendering engine handles the transformations directly through the compositor thread, without involving the main thread.
With these key points in mind, let's look at the issues of reflow, repaint, and why CSS animations are more efficient than JavaScript animations:
Reflow: Updates the geometric properties of elements (e.g., height). This means reflow requires updating the rendering pipeline starting from the layout stage.
Repaint: Updates the paint properties of elements (e.g., font color), directly entering the paint stage, bypassing the layout and compositing stages.
Efficiency of CSS animations: If we use JavaScript to animate elements, the browser must run these operations between each frame. Most of our displays refresh the screen 60 times per second (60 fps); only when each frame moves objects on the screen will the animation appear smooth to the human eye. If our animation frequently changes the geometric properties of elements using JavaScript, we will undoubtedly trigger reflow frequently. Even if our animation rendering keeps up with the screen refresh, JavaScript calculations run on the main thread, which can block our page. However, if we use CSS transforms to achieve animation effects, the browser will create a separate layer for the animated element, and subsequent transformations are handled directly on the compositor thread and submitted to the GPU. Compared to JavaScript animations that require JavaScript execution and style calculations, CSS animations are undoubtedly more efficient.
Additionally, let's talk about the CSS will-change property. The will-change property provides web developers with a way to inform the browser about which changes will occur on an element. After using it, the browser will create a separate layer for the relevant element, and when these changes occur, the rendering engine will handle the transformations directly through the compositor thread, thereby improving rendering performance. However, we should not overuse this property, as layer information is stored in memory, and too many layers can lead to slow page response or high resource consumption.
Streaming
The rendering pipeline starts when the rendering process receives a text/html byte stream response from the network process. In fact, a shared data pipeline is established between the rendering process and the network process. Once the network process receives the data, it places it into this pipeline, and the rendering process continuously reads the data from the other end, parsing it into the DOM. This means that the browser does not wait to receive the entire HTML before starting to render, which is a feature of the browser's progressive HTML rendering.
To fully utilize this capability of the browser, we can use server-side rendering (SSR) along with server-side streaming. Server-side streaming allows us to send HTML in chunks, enabling the browser to progressively render the HTML as it is received.
For example, in React18, we can call renderToPipeableStream to render our React tree as HTML into a Node.js Stream.This allows us to stream available HTML content while waiting for other data to load. This can greatly improve FCP (First Contentful Paint) and Time to First Byte (TTFB) metrics.
In addition to server-side streaming rendering, we can also use Service Worker to implement streaming response.
javascriptCopy code
Once event.respondWith() is called, the page whose request triggered the fetch event gets a stream response, and it continues to read from that stream as long as the Service Worker continues to enqueue() additional data. The response flowing from the Service Worker to the page is truly asynchronous, and we have complete control over the fill stream. That is, if we take the dynamic data of the streaming response on the server side and then add the cached data of the streaming response implemented through the Service Worker, we have a truly streaming fast response.